
- 4
- 0
It’s a key indicator of how well you understand the deployment and scalability of these powerful models in production.
When using models like GPT or LLaMA, it’s important to know how much GPU memory you need. This is crucial whether you’re working with a 7 billion parameter model or a much larger one. Understanding the calculations will help you choose the right hardware for running these models effectively. Let’s break down the math to estimate the GPU memory required for deployment.
Before that need latest updates checkout:
The Formula to Estimate GPU Memory
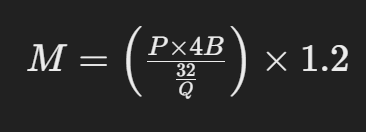
- M is the GPU memory in Gigabytes.
- P is the number of parameters in the model.
- 4B represents the 4 bytes used per parameter.
- Q is the number of bits for loading the model (e.g., 16-bit or 32-bit).
- 1.2 accounts for a 20% overhead.

Breaking Down the Formula
Number of Parameters (P):
- This represents the size of your model. For instance, if you’re working with a LLaMA model that has 70 billion parameters (70B), this value would be 70 billion.
Bytes per Parameter (4B):
- Each parameter typically requires 4 bytes of memory. This is because floating-point precision usually occupies 4 bytes (32 bits). However, if you’re using half-precision (16 bits), the calculation will adjust accordingly.
Bits per Parameter (Q):
- Depending on whether you’re loading the model in 16-bit or 32-bit precision, this value will change. 16-bit precision is common in many LLM deployments as it reduces memory usage while maintaining sufficient accuracy.
Overhead (1.2):
- The 1.2 multiplier adds a 20% overhead to account for additional memory used during inference. This isn’t just a safety buffer; it’s crucial for covering memory required for activations and other intermediate results during model execution.

Example Calculation
Let’s consider you want to estimate the memory required to serve a LLaMA model with 70 billion parameters, loaded in 16-bit precision:
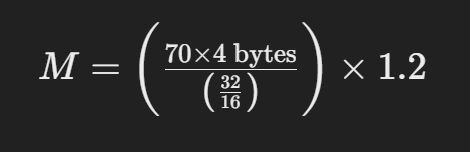
This simplifies to:
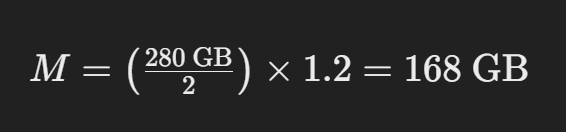
This calculation tells you that you would need approximately 168 GB of GPU memory to serve the LLaMA model with 70 billion parameters in 16-bit mode.
Practical Implications
Understanding and applying this formula is not just theoretical; it has real-world implications. For instance, a single NVIDIA A100 GPU with 80 GB of memory wouldn’t be sufficient to serve this model. You would need at least two A100 GPUs with 80 GB each to handle the memory load efficiently.

If you want to do this automatically with UI checkout this link.
https://huggingface.co/spaces/hf-accelerate/model-memory-usage
Leave a Reply