- 0
- 0
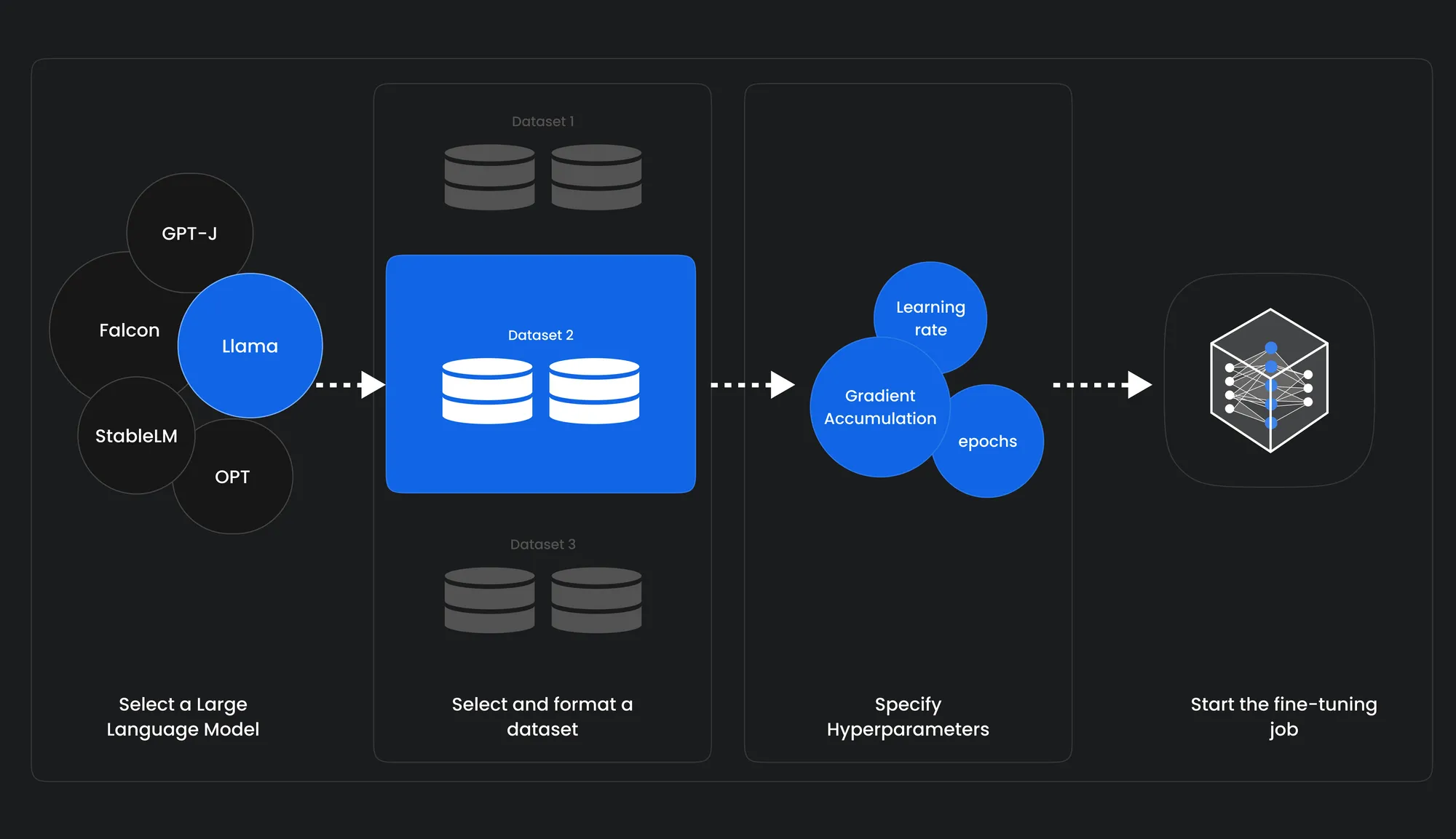
LLM fine-tuning is the process of retrain a pre-trained LLM on a new dataset, giving them LLM capabilities. It is used to improve the LLM’s performance on a specific task or data, or to adapt it to a new domain and build a domain-specific LLM
Large language models (LLMs) have transformed the field of natural language processing with their advanced capabilities and highly sophisticated solutions. These models, trained on massive datasets of text, perform a wide range of tasks, including text generation, translation, summarization, and question answering. But while LLMs are powerful tools, they’re often incompatible with specific tasks or domains.
Fine-tuning allows users to adapt pre-trained LLMs to more specialized tasks. By fine-tuning a model on a small dataset of task-specific data, you can improve its performance on that task while preserving its general language knowledge. For example, a Google study found that fine-tuning a pre-trained LLM for sentiment analysis improved its accuracy by 10 percent.
In this blog, we explore how fine-tuning LLMs can significantly improve model performance, reduce training costs, and enable more accurate and context-specific results. We also discuss different fine-tuning techniques and applications to show how fine-tuning has become a critical component of LLM-powered solutions.
Let’s get started!
History of Finetuning:
Fine-tuning is a machine learning technique used to adapt a pre-trained model to perform a specific task or address a particular dataset. The concept of fine-tuning has evolved alongside the development of deep learning models, particularly neural networks.
Early Approaches Before-2010:
Idea of transferring knowledge from one task to another is not new, but the formalization and systematic exploration. Before deep learning became mainstream, traditional machine learning models were fine-tuned manually by adjusting hyperparameters or feature representations.
Deep Learning and Pre-training (2010s):
Neural networks or deep learning, marked a significant shift in the way models were trained. Around 2013–2014, researchers started to realize the potential of pre-training large neural networks on massive datasets and then fine-tuning them on specific tasks with smaller datasets. This approach proved effective, especially when dealing with limited labeled data.
Word Embeddings and NLP (2013–2015):
In Natural language processing (NLP), word embeddings (e.g., Word2Vec, GloVe) demonstrated the benefits of pre-training on a large corpus and then fine-tuning on specific NLP tasks like sentiment analysis or named entity recognition. This idea laid the groundwork for more sophisticated models in NLP.
BERT and Transformer Models (2018):
The introduction of BERT (Bidirectional Encoder Representations from Transformers) marked a breakthrough in NLP. BERT and other transformer-based models demonstrated the power of large-scale pre-training on diverse tasks and fine-tuning for specific NLP applications, achieving state-of-the-art results on a wide range of benchmarks.
GPT Series (2018–Present):
Generative Pre-trained Transformers (GPT) series, including GPT-2 and GPT-3, demonstrated the capabilities of large-scale pre-training on diverse tasks. Fine-tuning GPT models allowed developers to leverage these powerful language models for a wide range of applications.
LLM Finetuning
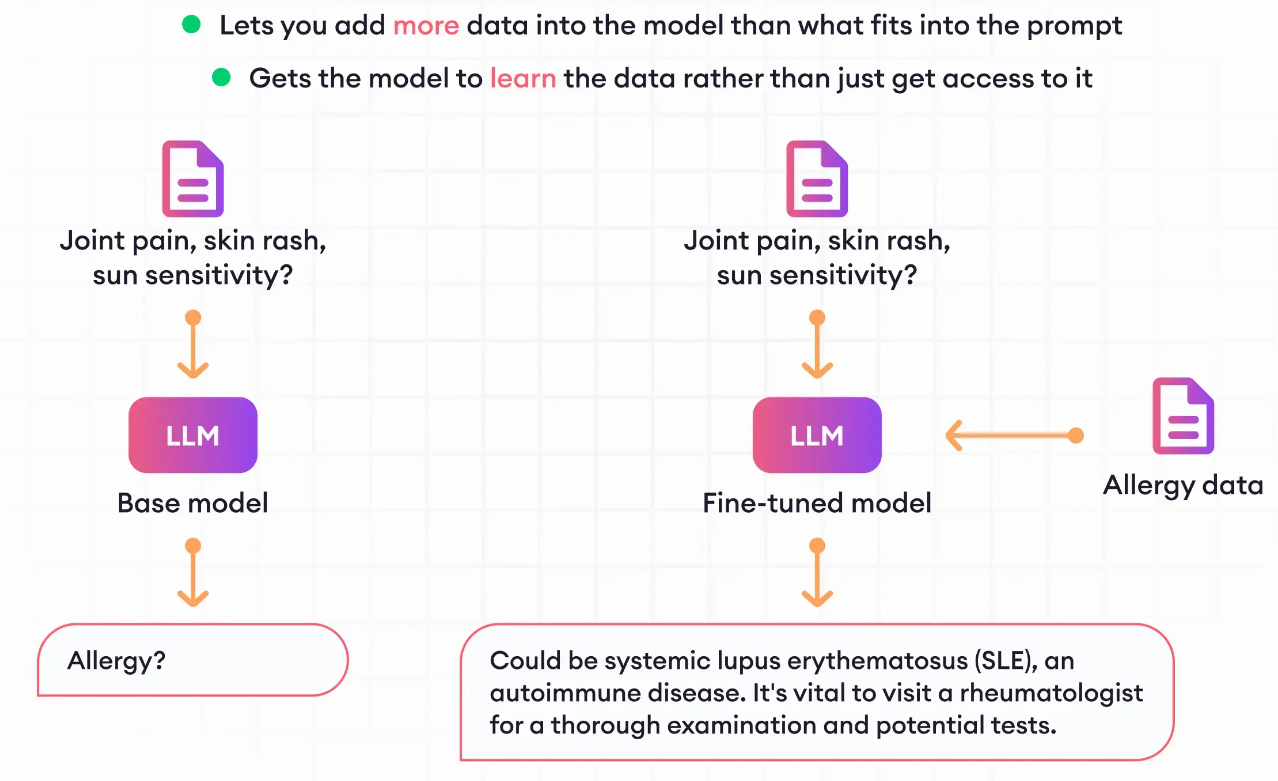
Fine-tuning allows to adapt pre-trained LLMs to more specialized tasks. By fine-tuning a model on a small dataset of task-specific data, you can improve its performance on that task while preserving its general language knowledge. For example, a Google study found that fine-tuning a pre-trained LLM for sentiment analysis improved its accuracy by 10 percent.
Conclusion:
Fine-tuning in Language Model (LLM) development has been crucial and Important For building llm enable solutions. From manual adjustments before 2010 to the transformative impact of deep learning and pre-training, fine-tuning has continually evolved. Word embeddings in NLP and the introduction of BERT and transformer models marked significant milestones. The GPT series further showcased the power of large-scale pre-training. Fine-tuning enables adapting LLMs to specialized tasks, significantly improving performance. fine-tuning is integral for optimizing language models and ensuring adaptability to diverse applications.
Leave a Reply